在我们上一节:主从复制(读写分离)中,我们可以看到,只有一个Master主机负责写,有多个slave主机负责读。那么如果Master挂了,如何保证可用性,实现继续读写?
什么是哨兵
Sentinel(哨兵)是用于监控Redis集群中Master状态的工具,是Redis高可用解决方案,哨兵可以监视一个或者多个redis master服务,以及这些master服务的所有从服务。 某个master服务宕机后,会把这个master下的某个从服务升级为master来替代已宕机的master继续工作。
(顺带提一句,即使后来之前的master重启服务,也不会变回master了,而是作为slave从服务)
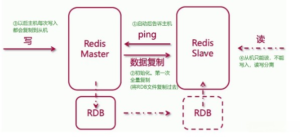
哨兵模式原理图
![图片[1] - Redis学习教程九:哨兵模式 - 正则时光](https://www.regular.cc/wp-content/uploads/2023/11/202209131417231.png)
实现哨兵模式示意图
![图片[2] - Redis学习教程九:哨兵模式 - 正则时光](https://www.regular.cc/wp-content/uploads/2023/11/2022091314281752.png)
实现哨兵步骤
1、 进入151主机的redis的解压目录,拷贝sentinel.conf到redis工作目录/usr/local/redis/ (当然这步看个人的安装情况)
cp sentinel.conf /usr/local/redis/2、修改配置文件
cd /usr/local/redis 然后: vim sentinel.conf
# 保护模式关闭,这样其他服务器就可以访问此台redis
protected-mode no
# 哨兵运行的端口
port 26379
# 哨兵模式是否后台启动,默认no,改为yes
daemonize yes
# 当运行daemonized时,Redis Sentinel写入一个pid文件,默认为/var/run/redis-sentinel.pid。可以指定自定义pid文件位置。
pidfile /var/run/redis-sentinel.pid
# log日志保存位置
logfile /usr/local/redis/sentinel/redis-sentinel.log
# 工作目录
dir /usr/local/redis/sentinel
# 核心配置。
# 第三个参数:哨兵名字,可自行修改。(若修改了,那后面涉及到的都得同步)
# 第四个参数:master主机ip地址
# 第五个参数:redis端口号
# 第六个参数:哨兵的数量。比如2表示,当至少有2个哨兵发现master的redis挂了,
# 那么就将此master标记为宕机节点。
# 这个时候就会进行故障的转移,将其中的一个从节点变为master
sentinel monitor mymaster 192.168.217.151 6379 2
# master中redis的密码
sentinel auth-pass mymaster 123456
# 哨兵从master节点宕机后,等待多少时间(毫秒),认定master不可用。默认30s,这里为了测试,改成10s
sentinel down-after-milliseconds mymaster 10000
# 当替换主节点后,剩余从节点并行同步的数量,默认为 1
sentinel parallel-syncs mymaster 1
# 主备切换的时间,若在3分钟内没有切换成功,换另一个从节点切换
sentinel failover-timeout mymaster 1800003、将上述修改好的配置文件,复制到129和130从机中。我这里直接使用scp命名复制
scp sentinel.conf root@192.168.217.129:/usr/local/redis/
scp sentinel.conf root@192.168.217.130:/usr/local/redis/4、因为配置文件中设定了自己的log存储位置,所以要把相应的文件创建出来,在151、129和130中都需要执行
mkdir /usr/local/redis/sentinel -p5、分别在151、129和130中执行下面命令,启动哨兵
redis-sentinel sentinel.conf6、可以在151主机中,进入到日志所在的目录下执行如下命令,让日志在前台显示查看监控
tail -f redis-sentinel.log![图片[3] - Redis学习教程九:哨兵模式 - 正则时光](https://www.regular.cc/wp-content/uploads/2023/11/2022091314432887.png)
测试哨兵模式:
一、关闭master的redis,查看redis集群主从机切换情况
1、先登录151主机redis,查看redis集群情况info replication
![图片[4] - Redis学习教程九:哨兵模式 - 正则时光](https://www.regular.cc/wp-content/uploads/2023/11/2022091314445687.png)
2、此时151为master,同理查看129和130。这两个为slave
3、 模拟151master节点宕机,把redis关闭
![图片[5] - Redis学习教程九:哨兵模式 - 正则时光](https://www.regular.cc/wp-content/uploads/2023/11/2022091314464342-1024x143.png)
继续查看各个节点的redis集群情况,
先看129
![图片[6] - Redis学习教程九:哨兵模式 - 正则时光](https://www.regular.cc/wp-content/uploads/2023/11/202209131447441.png)
在看130
![图片[7] - Redis学习教程九:哨兵模式 - 正则时光](https://www.regular.cc/wp-content/uploads/2023/11/2022091314480372.png)
结果符合预期。
二、重启151节点,查看redis集群情况,看是否还会恢复为主节点,还是作为从节点。
![图片[8] - Redis学习教程九:哨兵模式 - 正则时光](https://www.regular.cc/wp-content/uploads/2023/11/2022091314485134.png)
从测试结果可以看到,即使后来重启之前的master,也不会替换,而是作为slave。
相关衍生:解决原Master恢复后不同步问题
相信细心的同学会发现原来的Master(151)恢复成Slave后,他的同步状态不OK,状态为master_link_status:down,这是为什么呢?这是因为我们只设置了129和130的masterauth(redis密码),这是用于同步master的数据,但是151一开始是master是不受影响的,当master转变为slave后,由于他没有auth,所以他不能从新的master同步数据,随之导致info replication的时候,同步状态为down,所以只需要修改redis.conf中的masterauth为123456
![图片[9] - Redis学习教程九:哨兵模式 - 正则时光](https://www.regular.cc/wp-content/uploads/2023/11/2022091314503883.png)
一般master数据无法同步给slave的方案检查为如下:
- 1.网络通信问题,要保证互相ping通,内网互通。
- 2.关闭防火墙,对应的端口开发(虚拟机中建议永久关闭防火墙,云服务器的话需要保证内网互通)。
- 3.统一所有的密码,不要漏了某个节点没有设置